
在在线语言理解中,解析器增量地构建分层语法结构。这种结构构建过程的预测性一直是广泛争论的主题。之前的一项研究发现,当一个“wh”短语表示后面的“wh”分句和前面的分句之间的平行关系时(例如,约翰讲了一些故事,但我们不记得是哪个故事……),解析器会预言性地构建“wh”分句。这一观察证明了预测结构的建立。然而,该研究还表明,当wh短语表明不存在平行关系时,解析器不会做出预测(例如,John告诉了一些故事……与哪些故事……),这是对句法结构预测的潜在限制。至关重要的是,这些发现是有争议的,因为该研究没有观察到当消歧义输入时的处理困难,这表明预测的延续与全局语法结构(花园路径效应)不一致。有争议的结果可能是由于缺乏统计能力。因此,本研究进行了大规模的重复研究(324名参与者,24套材料)。结果表明,无论wh-phrase的类型如何,解析器都可以预测小句结构。还有花园路径效应的证据,支持解析器做出预测的发现。这些观察结果表明,人类解析器中固有的预测算法比以前的研究假设的更强大,并且解析器在修订期间试图构建全局语法结构。
在在线语言理解过程中,解析器分析每个单词并逐步构建分层语法结构。研究认为并观察到,在线语言理解是一个预测过程;在句子处理过程中,理解者对进入的要素产生假设(e.g., Crocker 1996;Fujita and Cunnings 2022,已出版;吉布森1991;戈雷尔1995;Ito et al. 2016, 2020;Kamide and Mitchell 1999;金伯尔1973;Lau等人,2006;Omaki et al. 2015;温伯格1993)。本研究从句法分析的角度探讨了这一预测过程的机制。
有证据表明,结构构建是一个预测过程(例如,Aoshima et al. 2004,2009;Kush et al. 2017;菲利普斯2006;Staub and Clifton 2006;吉田等人,2013)。吉田等人(2013)对本研究至关重要。Yoshida等人研究了解析器是否预测性地构建了一个跟随wh短语的子句结构,如下面的子字符串所示。
(1)
约翰讲了一些故事,但我们记不起是哪些故事了。
在(1)中,wh短语“which stories”表示后面有一个从句(TP)。这个wh-从句必须包含一个主名词短语(NP),一个动词短语(VP)和这个wh-短语的基本位置(t),以及适当的词汇内容,如我们记不起[NPt哪个故事][TP [NP你][VP听到t]](乔姆斯基1977;罗斯1969)。至关重要的是,在(1)中,wh子句的全部内容可以从第一个子句中恢复,因为这两个子句在句法结构和词汇内容上可以是平行的(即,John讲了一些故事,但我们不记得John讲了哪些故事)。如果一个介词伴随“wh”短语,破坏了平行关系,这种可恢复性就不成立了,如下所示。脚注1
(2)
约翰讲了一些故事,但我们记不起讲的是哪些故事。
吉田等人(2013)研究了解析器是否利用连通性效应来预测性地构建子句结构并从第一个子句中恢复其内容(Merchant 2005;Stjepanovi?,2008;Truswell 2014)和在线自反性解析(Sturt 2003)。连通性是指前面的短语似乎占据较低位置的现象。在线反身性解析是一个解析器通过在句子处理过程中搜索反身性的先行词来解析反身性的过程。例如,考虑下面的句子。
(3)
约翰/玛丽讲了一些故事,但我们不记得了
一个。
这些关于他的故事给汤姆留下了深刻的印象。
b。
这些故事给汤姆留下了深刻的印象。
这些句子类似于(1/2)中的子字符串,但在wh短语之后有明显的子句延续。此外,(3a/b)中的wh-短语包含一个反身物(“他自己”),该反身物在其结合域中参照依赖于一个命令c的NP(结合原则a;乔姆斯基1981)。C-command指的是节点之间的结构关系。本研究假设,当且仅当x不支配y且x的亲本支配y时,x c支配y (Reinhart 1976)。x的结合域是包含x、x的调控器和一个主体的最小NP或TP,而x不是其中的一部分(Chomsky 1981,1986)。根据这些定义,(3a/b)中的反身词与wh分句主语NP(“Tom”)相关,因为由于连通性效应,这个NP在其结合域中对其进行了c-命令(例如,[CP [NPt,这是关于他自己的故事][TP Tom对t印象深刻]])。然而,在(3a)中,如果解析器在遇到wh-短语时预测了小句结构,并从第一个子句中恢复其内容,那么第一个子句主语NP必须作为先行词(直到wh-子句主语NP出现,例如[TP [NPk John/Mary]]…[CP [NPt wh [NPk myself]] [TP [NPk] [VP t]]])。在(3a/b)中,第一个子句主语NP要么匹配(“John”),要么不匹配(“Mary”)反身代词的性别。我们知道,解析器在遇到自反后立即搜索结构许可的先行词,当两个np在性别上不一致时,处理困难就会出现(性别错配效应;例如,Sturt 2003)。研究通常使用阅读时间作为处理难度的指标,假设阅读时间随着处理难度的增加而变长。因此,在(3a)中,如果解析器预测了wh-子句并从第一个子句中恢复其内容,那么在性别不匹配(“Mary…myself”)条件下,在自反处的阅读时间应该比性别匹配(“John…myself”)条件下的阅读时间更长。在(3b)中,吉田等人预计性别错配效应不存在,因为介词wh-短语破坏了两个子句之间的平行关系,从而阻止了wh-子句的全部内容从第一个子句中恢复。在一项自定节奏阅读任务中,吉田等人证实了这些假设;他们在(3a)中观察到性别错配效应,但在(3b)中没有。
吉田等人(2013)的结果对句子解析理论有几个启示。一个是解析器预测性地构造大量的语法结构。这一含义源于这样一个事实,即预测的表征包含一个子句([CP wh [TP [NP] [VP]]])。另一个原因是解析器优先重用左上下文中的材料。在(3a)中的“wh-phrase”,不从第一个子句中恢复其内容而构建“wh-clause”是不允许的。Yoshida等人认为解析器循环材料是因为它倾向于最大化子句之间的并行性([TP John讲了一些故事]…[TP John讲了哪些故事];参见Carlson 2001;Frazier et al. 1984;Hall and Yoshida 2021;Kim et al. 2020;Knoeferle and Crocker 2009)。
另一个对本研究至关重要的含义是,当wh短语表明两个子句之间不存在平行关系时,解析器无法预测子句结构。如前所述,吉田等人(2013)假设(3b)中不存在性别错配效应,因为介词wh-短语阻止了从第一个子句中恢复wh-子句的全部内容。然而,这种不可恢复性并不会阻止解析器构建子句的延续,并在第一个子句的主语np和wh-子句之间在wh-短语处假定联合引用(即,可以将(3b)分析为[TP [NPk] [VP V1]]…[CP [PPt] [TP [NPk] [VP V2 t]]], V1≠V2)。鉴于(3b)中的反身词与wh-从句主语NP共指,没有性别错配效应可能表明解析器没有预测性地构建小句结构。换句话说,吉田等人的观察可能指向句法结构预测的潜在限制。如果这种解释成立,我们必须假设,在某些情况下,解析器仅在并行性提供提示时才预测子句结构(即,预测是并行性驱动的过程)。这种潜在的限制在理论上是至关重要的,考虑到wh短语后面的小句结构对于句子的格式良好是必要的,并且有证据和论点表明解析器在句子处理过程中预测性地构建强制性结构(增量许可;阿布尼1986;Aoshima et al. 2004;克罗克1996;Frazier and Clifton 1996;吉布森1991;Gibson et al. 1994;戈雷尔1995;普里切特1988、1991、1992;温伯格1999)。也就是说,根据增量许可理论,解析器在遇到(3a)和(3b)中的wh-短语时,应该预先构建小句结构,而Yoshida等人在(3b)中的观察结果可能与这一理论相矛盾。
或者,(3b)中没有性别错配效应可能表明解析器预测了wh-子句,但假设了与第一个子句主语NP的不相交引用(例如,没有预测词汇内容;(氮磷钾约翰/玛丽)……(CP [PPt wh] [TP (NPi)[副总裁t]]])。这种解释与增量许可理论是兼容的,如果它是有效的,我们必须解释为什么解析器避免在wh-短语处的共同引用。
如上所述,吉田等人(2013)的结果对句子解析理论具有重要意义。然而,他们的结果有一个问题:在(3a)中,他们的参与者在性别匹配条件下没有表现出对wh分句主语NP的处理困难。这个NP的出现表明,从第一个子句中恢复的材料与整体语法结构不相容。重要的是,有大量证据表明,当输入的单词不适合当前结构时,阅读时间会增加(例如,Clifton 1993;Cunnings and Fujita 2021;弗雷泽和雷纳1982;Fujita 2021 b;Fujita and Cunnings 2020, 2021a, 2021b;Slattery et al. 2013;Sturt et al. 1999;Tabor and Hutchins 2004)。这种花园路径效应(Frazier and Rayner 1982)被认为是由于解析器难以将消歧输入整合到当前结构中,并试图构建全局语法结构(修订)。考虑到这些研究,我们可以预期在(3a)中的wh分句主语NP上会有一些处理困难。因此,在wh子句主语NP中没有花园路径效应可能与解析器预测子句结构的发现相矛盾。如果吉田等人观察到的性别不匹配效应是一种实验人工产物,如果他们在消歧义区域的观察结果代表了句子解析的潜在机制,我们必须假设,至少在某些情况下,人类解析器不够强大,无法像TP那样预测如此大量的句法结构。
然而,对于为什么吉田等人(2013)没有观察到花园路径效应,还有其他解释。一种是解析器没有启动修订过程,或者在消除歧义后立即停止修订过程,因为在消除歧义后预测的延续是可以容忍的。在心理语言学中,有些人采用这种方法。例如,“足够好”方法将语言理解视为一种启发式过程,而不是一种算法过程,并假设理解者采用快速而节俭的启发式过程,即使这些过程不符合语法原则(例如,Christianson等人,2001;费雷拉和帕特森2007;Slattery et al. 2013)。这种预设的一个后果是,理解者创造了与全局语法结构不相容的表征。按照“足够好”的方法,我们可以将(3a)中花园路径效应的缺失解释为表明预测的延续足以理解句子。如果句子处理遵循简单的启发式过程,我们需要指定解析器在什么情况下省略修订过程,以及它构建了什么结构(例如,消歧输入附加在哪里?)
或者,对比结果可能是由于缺乏统计能力。Yoshida et al.(2013)进行了一项有40名参与者、24套材料的自定节奏阅读实验。这些数字在句子处理研究中是典型的。然而,考虑到Yoshida等人测试的实验材料结构复杂,对效应的精确估计可能需要很高的统计功率。因此,本研究采用324名参与者和24组材料的词性迷宫任务,对Yoshida等人的实验进行了高功率复制。
该实验是在线进行的,通过多产网站(https://www.prolific.co)招募了324名母语为英语的人。这些参与者年龄超过18岁,在英国长大和生活,是英国公民。
实验包含Yoshida et al.(2013)的24组实验材料,如下图(4a-d)所示。
(4)
Wh-NP,性别匹配。
珍妮特的祖父在家庭聚会上讲了一些故事,但我们记不起在聚会上给珍妮特的哥哥留下深刻印象的是哪些关于他自己的故事。
(4 b)
性别不匹配。
贾斯廷的祖母在家庭聚会上讲了一些故事,但我们记不起派对上哪些关于他自己的故事给弟弟留下了深刻的印象。
(4)
Wh-PP,性别匹配。
珍妮特的祖父在家庭聚会上讲了一些故事,但我们不记得是哪些关于他的故事给珍妮特的哥哥留下了深刻的印象。
(4 d)
性别不匹配。
贾斯汀的祖母在家庭聚会上讲了一些故事,但我们不记得是哪些关于他自己的故事给弟弟留下了深刻的印象。
在(4c/d)中,介词伴随“wh”短语,但在(4a/b)中没有。在(4a/b)中,wh-子句的全部内容可以从第一个子句开始恢复,直到wh-子句主语NP出现。第一个子句主语NP在(4a/c)中与反身代词的性别匹配,在(4b/d)中不匹配。
如果结构构建是一个预测过程,那么有三种假设是可以想象的。一个是,只有当并行性为子句结构提供线索时,解析器才会预测wh-子句。如果这一假设正确,则反身性别错配效应应该只发生在wh-NP条件下,且(4b)的阅读时间长于(4a)。此外,由于花园路径效应(例如,Frazier和Rayner 1982),这种阅读时间模式应该在消歧义区域(“兄弟”)方向反转。如果解析器预测了wh-NP和wh-PP条件下的子句结构,但仅在wh-NP条件下假设第一个子句的主语np和wh-子句之间存在联合引用,则应该得到类似的结果。如果解析器预测性地构建了wh-子句,并且不管介词是否存在都假定存在共指,那么在wh-NP和wh-PP条件下都应该出现性别不匹配效应和花园路径效应。因此,关键是在反射区和消歧义区是否出现了显著的性别主效应或显著的性别交互作用。
本研究采用词性迷宫任务(Forster et al. 2009;Witzel et al. 2012)。在该任务中,参与者逐字阅读每个句子,每个单词都有一个假单词,并需要按下正确单词对应的按钮(见图1)。因此,从迷宫任务中获得的数据包括阅读次数和判断反应次数。为了便于解释,本研究将这一衡量标准称为阅读时间。当参与者选择一个假词时,试验立即终止,并开始下一个试验。词法迷宫任务在PCIbex Farm中进行(Zehr and Schwarz 2018),实验文件是使用在线代码创建的(Boyce et al. 2020;2021年Fujita)。实验开始时进行了四次练习,随后以伪随机的顺序呈现了24个实验句子和72个填充物。
图1
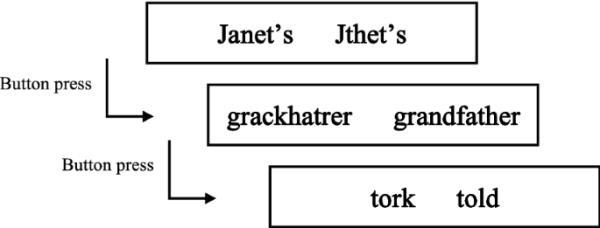
词法迷宫任务的一个例子
因变量是四个区域的对数变换阅读时间。这些区域分别是自反性(“他自己”)、后自反性(“来自”)、消歧义(“兄弟”)和后消歧义(“曾经”)区域。数据分析前,不包括小于300 ms或大于7000 ms的读取时间。这些异常值所代表的数据不到0.01%。对于数据分析,采用随机效应的全方差-协方差矩阵的线性混合效应模型(最大模型;Barr et al. 2013)在R (R Core Team 2020)中使用lme4软件包(Bates et al. 2015)分别对每个区域进行了拟合。固定效应为wh_type (wh_np / wh_pp)、gender (match/mismatch)及其相互作用的和编码(0.5/ -0.5)主效应。当最大模型不收敛时,首先去除随机效应相关性,然后迭代去除方差最小的随机效应,直到模型收敛。为了解释结果,从t分布中估计p值(Baayen 2008),小于0.05的p值被解释为具有统计学意义。数据和分析代码可从https://osf.io/rh4xz获得。
摘要
介绍
方法
结果
讨论与结论
数据可用性
笔记
参考文献
作者信息
道德声明
#####
表1总结了统计分析,图2显示了(后)消歧义和(后)反射区域的阅读时间。
表1(后)自反和(后)消歧义区域的统计分析摘要
图2
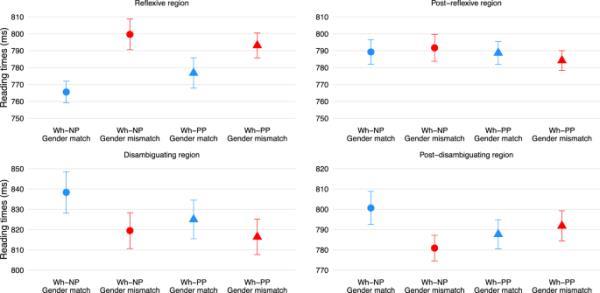
(后)反身和(后)消歧义区域的阅读时间。误差条是标准误差
分析揭示了性别的显著主要影响,性别不匹配条件下的阅读时间比性别匹配条件下的阅读时间更长。性别交互作用的h型差异无统计学意义。
无统计学意义的影响。
性别的主效应显著,性别匹配条件下的阅读时间比性别不匹配条件下的阅读时间更长(即花园路径效应)。
分析显示,性别交互作用显著的h型。作为后续分析,我们拟合了一个嵌套对比的附加模型,以检验性别在每个h型水平内的影响。该分析揭示了花园路径效应在wh-NP条件下存在(估计=0.019,SE=0.01, t=2.19, p=0.29),而在wh-PP条件下不存在(估计=-0.006,SE=0.01, t=-0.71, p=0.479)。
本研究使用词法迷宫任务对吉田等人(2013)的研究进行了大规模复制,以探索预测结构构建过程。实验揭示了性别错配效应在反身,关键是不相互作用的类型。性别交互中“wh”类型的缺失表明,在“wh-短语”中,无论“wh-短语”的类型如何,解析器构建的整个“wh”子句的主语NP与第一个子句主语NP协同。这一发现与吉田等人部分不一致,吉田等人只在wh-NP条件下观察到性别错配效应。此外,分析还揭示了wh-NP和wh-PP条件下消歧义区域的花园路径效应,支持了解析器在这些条件下预测性地构建wh-子句的证据。花园路径效应的存在还表明,解析器试图在消除歧义的基础上构建全局语法结构,这一发现与“足够好”语言理解的一种可能反射相反。分析还表明,花园路径效应仅在wh-NP条件下存在于消歧后区域。这一观察结果表明,在这种情况下,花园路径效应有两个位点(即wh分句主语NP和动词)。
解析器在wh-NP和wh-PP条件下都能预测构建子句结构,这一发现表明句子解析的预测机制比吉田等人假设的更为强大(即并行驱动预测)。预测解析过程的基础是什么机制?
语言理解理论通常假设左角解析(一类自顶向下的解析算法;参见Aho and Ullman 1972;Grune and Jacobs 2008;Johnson-Laird 1983)作为句子解析的基本机制。然而,该算法不够强大,无法在wh-短语处投射整个条款结构(见Yoshida et al. 2013, pp. 290-291)。正如引言中所指出的,如果我们假设人类解析器立即并逐步构建必要的结构,那么wh-NP和wh-PP条件下的预测都是可以解释的(回想一下,在wh-短语之后的小句结构对于句子的格式良好是必要的)。增量许可理论认为在线句子处理是一个即时增量满足语法约束的过程(例如,Abney 1986;Aoshima et al. 2004;克罗克1996;Frazier and Clifton 1996;吉布森1991;Gibson et al. 1994;戈雷尔1995;普里切特1988、1991、1992;温伯格1999)。在wh-NP和wh-PP条件下,wh-短语的出现表示TP的开始,TP必须包含主语NP、VP和wh-短语的基本位置。因此,增量许可解析器在遇到wh-短语时应该构建整个wh-子句,这解释了本研究中观察到的预测过程。
与预测机制相关的另一个要讨论的问题是,为什么解析器假定第一个子句和wh子句的主语np之间存在相互引用。正如引言中所指出的,吉田等人(2013)认为,解析器最大限度地提高了两个子句之间的并行性,从而导致了wh-NP条件下的联合引用。在wh-PP条件下,并行性不成立。然而,这两个子句在句法结构和词汇内容上仍然有一些相似之处。例如,增量许可解析器认识到这些子句由相似但不完全相同的语法结构组成,并共享一个词法项(例如,“故事”),它们遵循彼此的VP(例如,[CP [TP [NP] Janet的祖父][VP告诉[NP一些故事]]]]…[CP [TP [NP] [VP [PP与哪些故事]]]])。此外,wh短语(“哪些故事”)与第一个子句中的NP(“一些故事”)有关联(假设脚注1)。这些相似性可能导致解析器将两个子句想象为相关的,并期望它们尽可能同质,从而导致两个主语NP ([TP [NPi] [VP V1]]…[CP [PPt wh] [TP [NPi] [VP V2 t]]], V1≠V2)之间的联合引用。这个假设解释了为什么解析器不假设与所有格NP共指。回想一下,本研究测试了吉田等人使用的实验材料。在这些材料中,第一个从句主语NP的所有格NP在性别上总是不同的(例如,“Janet/Justin的祖父/祖母”)。结果表明,性别操纵不影响whp - pp条件下的阅读时间。我们可以通过假设解析器期望在介词“wh-phrase”的情况下两个子句之间的最大相似性来解释这一观察结果。
或者,解析器可能倾向于联合引用,因为将新引用集成到当前结构中会产生处理成本。一些文献中的研究提出了类似的概念(例如,Altmann和Steedman 1988;Gibson 1998,2000)。例如,Gibson(1998)认为引入新参照的干预因素会增加记忆成本,从而导致处理困难。在wh-NP和wh-PP条件下,wh分句主语NP介于wh短语的着陆点和基础位置之间。因此,Gibson的假设预测,当嵌入主体NP引入新的指称物时,记忆成本会增加。鉴于解析器通常不赞成在句子处理过程中进行代价高昂的分析(例如,De Vincenzi 1991;Fodor and Inoue 2000;Frazier 1979),主体np之间联合指称的假设可能(部分)是由于避免了新的指称,特别是在wh-PP条件下。脚注4
总结一下到目前为止的讨论,解析器在遇到wh-短语时预测性地构造整个wh-子句,以立即和增量地满足语法约束。然后,解析器期望连接的字符串最大程度地相似,并且/或者尝试避免新的引用,从而导致两个主题np之间的联合引用。因此,解析器从wh-NP条件中的第一个子句中恢复wh-子句的全部内容(主语NP和VP),而在wh-PP条件中,它只回收主语NP。这一假设与我们在消歧后区域(即wh-从句动词)观察到的情况是一致的。回想一下,仅在wh-NP条件下,消歧后区域显示花园路径效应。如果我们假设解析器在wh-NP条件下需要修改wh-子句主语NP和VP,而在wh-PP条件下只需要修改wh-子句主语NP,那么这个发现是可以解释的(见图3和图4)。
图3
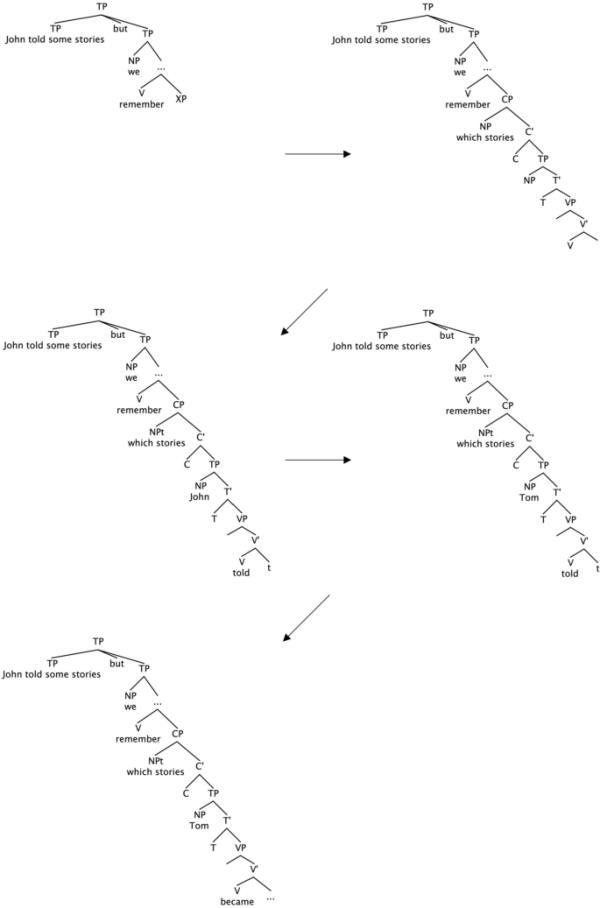
在wh-NP条件下的解析过程(John讲了一些故事,但我们不记得Tom对哪些故事印象深刻)
图4
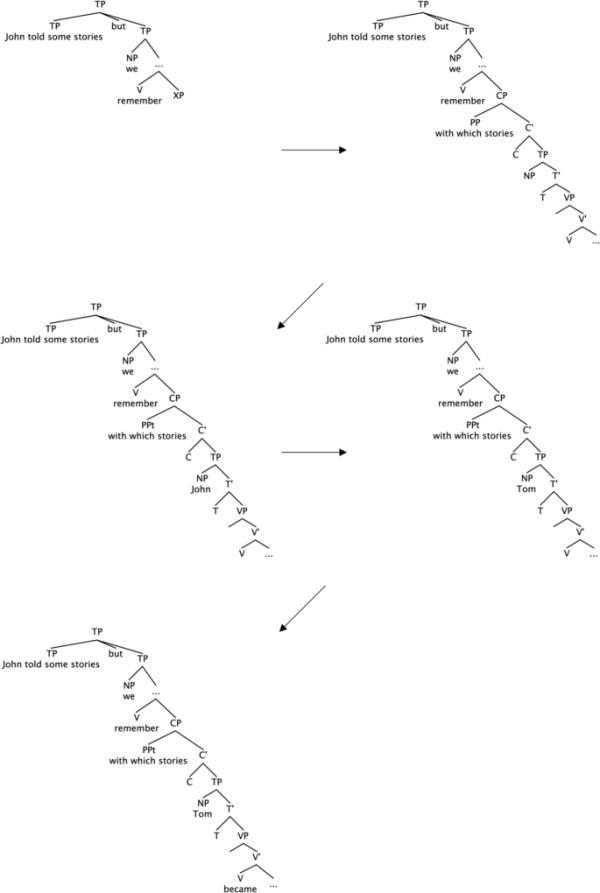
whp - pp条件下的解析过程(John讲了一些故事,但我们记不起Tom对哪些故事印象深刻)
最后,我讨论了吉田等人(2013)与本研究之间的不同观察结果是由于所采用任务的差异造成的可能性。正如引言中提到的,吉田等人使用自定节奏阅读来测量阅读时间,而本研究使用词汇迷宫任务。迷宫任务可能影响结果的一个独特特征是,由于在两个候选词之间进行强制选择,它们迫使对每个词进行增量分析(例如,Forster等人,2009年),这可能会阻止读者在阅读时策略性地创造不明确的表征。换句话说,当来自自定节奏阅读任务的数据表明与语法原则不兼容的处理模式时,它们通常反映的是策略上的规范不足,而不是人类解析器的内在本质(这有时会导致误解,认为规范不足是句子处理的普遍属性)。请注意,我并不是想说迷宫任务优于自定节奏阅读任务。我的观点是,在自然阅读环境中观察到,自定节奏阅读可能是研究语言理解行为方面(例如,规范不足)更有利的工具,而迷宫任务可能是研究句子处理机制的更合适的选择。在这一假设下,可以想象吉田等人与本研究之间的不同观察结果,如花园路径效应的存在或不存在,是任务特定策略的结果。
总之,本研究表明/证实了以下几点:
1.
在在线句子处理过程中,人类解析器预测地构建分层语法结构。
2.
这种预测结构的构建源于解析器试图尽早满足语法约束。
3.
解析器试图最大化连接字符串之间的相似性,这导致从第一个子句中恢复wh子句的全部或部分内容。
4.
解析器还可以在子句的主题np之间假定联合引用,以避免将新引用集成到当前结构中所产生的处理成本。
5.
当消歧输入表明预测构建的结构在全局上是不符合语法的时,解析器进行修正以构建全局语法结构。
资讯来源:http://lib.mituchina.com/news/57695/
点击分享到









